
Kubernetes
Profundizando en arquitectura
Hasta ahora solo se ha demostrado el trabajo de docker en una única máquina Para escalar la infraestructura es necesario pensar en crecimiento externo.
Los contenedores están jugando un rol importante para el desarrollo de aplicaciones y el despliegue de las mismas. En el historial de grandes sistemas en centros de datos se han usado máquinas de metal puro que luego de ser compradas suelen tener tres años de vida útil para posteriormente depreciarse. Este ciclo se viene repitiendo una y otra vez. Estás máquinas viejas pueden ser pensadas como mascotas, pero lo que realmente se quiere es tener un ganado. Bajo este contexto el hecho de perder una vaca, no significa que se vaya a perder la producción de leche. Eventualmente se puede conseguir otra vaca. Este es el tipo de modelo al que las infraestructuras se están proyectando, en vez de tener una máquinas con características especificas que al ser afectada pueda causar un falló total de la aplicación.
La transición de máquinas específicas a rebaños de máquinas, es algo que puede realizarse con máquinas virtuales, pero dichas máquinas no están diseñadas para ser usadas en periodos cortos de tiempo. Adicionalmente, eliminar una maquina virtual es un proceso dispendioso. Por otro lado, los contenedores son rápidos de crear y destruir dando como resultado un montaje eficiente de infraestructura. Cabe resaltar que la informática tiende hacia tiempos de inicio y parada aún más rápidos. Si se lleva este concepto al límite, es posible crear un contenedor con una simple petición y apagarlo con otra. Esta versatilidad esta abriendo cabidad al concepto de serverless computing y ya hay algunos frameworks que promueven el uso de este concepto.
Ahora, evidentemente hay varios retos a sobrellevar con la escritura de aplicaciones contenerizadas. El primer inconveniente es que las orgranizaciones mantienen sus viejas prácticas y por lo tanto sus monólitos. Ya hay una cultura organizacional establecida al rededor del monolito, y la transición al uso de micro servicios es un proceso gradual que debe cultivarse en el trabajo interno de los equipos de desarrollo. Con este nuevo enfoque, se va a tener personas de cualquier parte del mundo generando aportes al desarrollo de software y eso requiere procesos de validación y auditoria al momento de revisar que cambios de código van a publicarse en la aplicación. Eso implica que la creación de software va ser una especie de formulario. Este formulario es a veces llamado la ley de Conway, la cual dice que las organizaciones diseñan sistemas que imitan sus propias estructuras de comunicación. En otras palabras, una empresa no puede producir microservicos si es una organización con producción en cascada. Por lo tanto, se pueden perder los benecficios del patrón de microservicos por esquemas de la organización.
El segundo inconveniente con la implementación aplicaciones en contenedores son los obstáculos técnicos. Este patrón requiere de procesos automatizados bien ejecutados, El movimiento de piezas hace que los sistemas estén en capacidad de hacer descubrimientos dinámicos que luego se deben monitoriar. Una pregunta válida es si los desarrolladores deberián escribir estos sistemas de automatización por cuenta propia, y la respuesta es no. Estas implementaciones requieren de mucho trabajo y por ende es mejor encontrar un sistema que funcione y deje la puerta abierta al cambio para infraestructuras venideras, como Kubernetes.
Como me enteré the Kubernetes (a.k.a k8)
Uno de los retos a los cuales muchas personas se someten en el mercado de la informática, es escoger entre una gran variedad de teconologías para hacer tareas puntuales. Está búsequeda puede llegar a ser abrumadora, ya que también determina que aprendizajes se deben ejecutar. Para atender esta elección, es conveniente guiarse de alguién con más experiencia y respaldar la decisión con el aporte y el estado de la comunidad detrás de la tecnología.
Para el manejo de aplicaciones una de las mejores herramientas es Kubernetes. Kubernetes es una herramienta que observa a los contenedores en un nivel superior. La abstracción sobre la que opera Kubernetes puede llegar a tener mucho sentido.
Qué es Kubernetes
Docker hace que el despliegue y la ejecución de los contenedores sea sencillo. El próximo paso lógico es usar docker en todas las máquinas y buscar una forma para integrarlas. El empaquetamiento de contenedores corresponde al 5% del problema. Los inconvenientes reales vienen cuando se trabaja las configuraciones de las aplicaciones, los descubrimientos de servicios, la administración de actualizaciones y el monitoreo de las máquinas.
Todas estas carácteristicas se construyen sobre docker, y la recomendación es tomar ventaja de una plataforma como Kubernetes que se encargue de manejar toda esta complejidad de infraestructura.
Kubernetes provee un nuevo conjunto de abstracciones que van más allá de las bases del despliegue de contenedores, y habilita a que el desarrollador se enfoque en el panorama general.
Anteriormente el punto a tratar era el despliegue de aplicaciones en máquinas individuales, lo cual funciona en flujos de trabajo limitados. Kubernetes permite abstraer las máquinas individuales de una forma que el grupo de máquinas se trate como una única máquina ĺógica. La aplicación se convierte en un ciudadano de primera clase que habilita su administración a través del uso de abstracciones de alto nivel.
En Kubernetes se puede describir un conjunto de aplicaciones y como deberian interactuar entre ellas. Así es como Kubernetes resuelve toda esta complejidad.
Configurando Kubernetes
Use el siguiente directorio de proyecto:
cd $GOPATH/src/github.com/udacity/ud615/kubernetes
o si está en el repositorio del curso:
cd kubernetes
Nota: En cualquier momento puede limipiar la aplicación ejeuctando el script
cleanup.sh
Aprovisiona un clúster de Kubernetes con GKE mediante gcloud
Kubernetes se puede configurar con muchas opciones y complementos, pero puede llevar mucho tiempo arrancar desde cero. En esta sección, iniciará Kubernetes con Google Container Engine (GKE).
GKE es un Kubernetes alojado por Google. Los clústeres de GKE se pueden personalizar y admiten diferentes tipos de máquinas, cantidad de nodos y configuraciones de red.
Utilice el siguiente comando para crear su clúster y utilizarlo durante el resto de esta sección.
gcloud container clusters create k0 --zone us-central1-a
Pequeña demostración de Kubernetes
La forma más sencilla de comenzar con Kubernetes es usando el comando kubectl. Para correr una única instancia del contenedor de NGINX se ejecuta el siguiente comando:
kubectl run nginx --image=nginx:1.10.0
pod/nginx created
Como se puede observar, el mensaje de salida indica que el pod NGINX ha sido creado. Más adelante se desarrollará el concepto de pod, pero por ahora es suficiente saber que los pods son los contenedores desplegables en kubernetes.
Para revisar el contenedor de NGINX que se acaba de crear se esta ejecutando, se usa el siguiente comando.
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 20h
Una vez se sepa que el contenedor de NGINX se esta ejecutando, se puede exponer por fuera del contexto de kubernetes con el siguiente comando:
kubectl expose deployment nginx --port 80 --type LoadBalancer
kubectl expose deployment nginx --port 80 --type NodePort
service "nginx" exposed
Detrás de escenas, kubernetes ha creado un balanceador de carga externo con un dirección IP pública adjunta. Cualquier cliente que golpee esta dirección IP pública, será enrutado a los pods que soportan el servicio. Pare este caso puntual, se tiene el pod de NGINX.
Para enlistar los servicios que se están ejecutando, se usa el siguiente comando:
kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.3.240.1 <none> 443/TCP 20h
nginx ClusterIP 10.3.240.40 443/TCP 31h
En la salida se observa la IP pública que se puede utilizar para golpear el contenedor NGINX remotamente.
Kubernetes soporta una flujo de trabajo sencillo fuera del la caja usando los comandos run y expose de kubectl. Con este breve tour por Kubernetes, es tiempo de profundizar en cada uno de los componentes y las abstracciones.
Hoja de trucos para kubernetes
Este primera aproximación a kubernetes puede ser algo abrumadora. No hay por que tener, con el tiempo va a ver mayor familiarización con la plataforma. Una ayuda efectiva es la hoja de trucos de comandos de kubernetes.
Introducción a los pods
El núcleo de kubernetes son los pods. Los pods representan una aplicación lógica. Los pods mantienen una colección de uno o más contenedores. Generalmente, cuando se tienen múltiples contenedores con una fuerte dependencia entre ellos, se deben empaquetar dentro de un único pod.
En el ejemplo de referencia, se usa un pod que tiene dos contenedores; uno del monolito y otro de NGINX.
Los pods también tienen volúmenes. los volúmenes son divisiones de datos que viven tanto tiempo como el pod y pueden ser utilizados por cualquiera de los contenedores ese pod. Esto es posible porque los pods proporcionan un espacio de nombres compartido para su contenido.
Eso significa que los dos contenedores dentro de pod de ejemplo se pueden comunicar entre ellos, y compartir los volumenes adjuntos.
Los pods también comparten un espacio de nombre de red, lo que implica que hay una dirección IP por pod.
La siguiente ilustración sirve para aglomerar todos los conceptos que componen un pod:
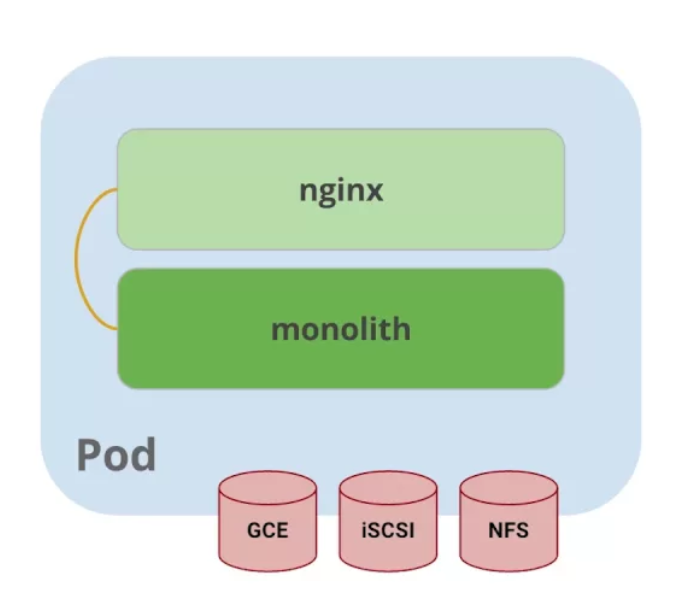
Figure 1: El cliente envía una solicitud de log in
Creando pods
Los pods son creados a través de archivos de configuración pod. A continuación se revisará el modelo del archivo de configuración del pod que se está usando como ejemplo:
$ cat pods/monolith.yalm
apiVersion: v1
kind: Pod
metadata:
name: monolith
labels:
app: monolith
spec:
containers:
- name: monolith
image: udacity/example-monolith:1.0.0
args:
- "-http=0.0.0.0:80"
- "-health=0.0.0.0:81"
- "-secret=secret"
ports:
- name: http
containerPort: 80
- name: health
containerPort: 81
resources:
limits:
cpu: 0.2
memory: "10Mi"
Se tiene información relevante en este archivo, como por ejemplo, que el pod solo tiene un contenedor llamado monolith. También se puede observar que se están pasando tres argumentos al contenedor al momento de iniciarse y por último, el puerto 80 está abierto para tráfico HTTP, y el puerto 81 para health checks.
Para crear el pod del monolith, se usa kubectl con el siguiente comando:
$ kubectl create -f pods/monolith.yaml
pod "monolith" created
Para examinar los pod, se ejecuta el siguiente comando para obtener una lista de todos los pods que se están corriendo en el espacio de nombre por defecto:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
monolith 1/1 Running 0 11s
nginx 1/1 Running 0 8d
Se tomará algunos segundos mientras que el pod monolith este arriba y corriendo, ya que el contenedor de la imagen del monolíto necesita ser traído desde el docker hub antes de poder correrlo.
Con el comando de descripción, se obtiene varia información sobre el pod monolito, desde la dirección IP hasta el log de eventos. Esta información resulta práctica para la solución de problemas.
$ kubectl describe pods monolith
Como se puede observar, Kubernetes hace fácil la creación de pods a través de un archivo de configuración y la visualización de los mismo cuando se están corriendo. En este punto se tiene la habilidad de crear todos los pods que de acuerdo a los requisitos de despliegue.
Interactuando con los pods
Los pods son ubicados por defecto en una dirección IP privada y no puede ser alcanzada por fuera del cluster. El siguiente comando permite mapear un puerto local con un puerto dentro del pod.
$ kubectl port-forward monolith 10080:80
Forwarding from 127.0.0.1:10080 -> 80
La recomendación para la interacción con pods es usar dos terminales, una para correr el comando port-forward y otra emitir los comandos del kernel, como por ejemplo:
$ curl http://127.0.0.1:10080
{"message":"Hello"}
De esta forma, se establece la comunicación con el pod. Si se intenta golpear el /secure endpoint, sin haber iniciado sesión, se obtiene el error de
autorización fallida.
$ curl http://127.0.0.1:10080/secure
authorization failed
Es importante recordar, que para iniciar sesión se hace la petición al endopoint respectivo, con sus debidas credenciales.
$ curl -u user http://127.0.0.1:10080/login
Enter password:
De este modo se obtiene el JWT, el cual debe ser enviado como parámetro para consultar el secure endpoint.
Otro comando importante es el que muestra los logs para el pod del monolito:
$ kubectl logs monolith
La bandera -f de este comando es usada para habilitar una corriente con los logs que se están mostrando en tiempo real.
$ kubectl logs -f monolith
El comando exec se usa para ejecutar una vista interactiva dentro del modelo de pod.
$ kubectl exec monolith --stdin --tty -c monolith /bin/sh
Este comando resulta útil cuando se perecise solucionar problemas que se presentan dentro del contenedor. Por ejemplo, una vez dentro del shell del contenedor del monolito, se puede probar la conexión externa a través del comando ping.
$ ping -c 3 google.com
Una vez terminada la sesión en el shell, es importante asegurarse de cerrar la sesión con el comando exit.
$ exit
En conclusión, la interacción con pods is fácil de lograr gracias a los comandos suministrados por kubctl. Desde intentos para golpear el contenedor remotamente, hasta iniciar sesión en el shell interno del contenedor para la resolución de problemas. Kubernetes proveé todo lo que se necesita para ponerse en marcha.
Revisión general de MHC (Monitoring Health Check)
Algunas veces un contenedor dentro de un pod puede estar montado y corriendose, pero la aplicación dentro del contenedor puede esta funcionando mal, como por ejemplo, que el código de la aplicación este bloqueado.
Kubernetes fue construido para soportar y dar garantias sobre que la aplicación se este ejecutando correctamente a través de controles de salud y preparación, implementados por el usuario.
Las sondas de preparación (readiness en inglés), indican cuando el pod estalisto para el tráfico de servidor. Si este control falla, entonces el contenedor será marcado como no listo y sera descartado por cualquier balanceador de carga.
Las sondas de vivacidad (liveness en inglés) indican que un contenedor está vivo. Si la sonda de vitalidad falla multiples veces, entonces el contenedor será reiniciado.
Una referencia visual puede ser la siguiente. En este ejemplo se muestra un pod con un contender app v1 y un demonio de kubernetes llamado kubelet. Kubelet es responsable de la salud del pod, y va a ejecutar el control de vida. Para este caso el contenedor es muerto y se utiliza el color rojo del para indicar dicho estado.
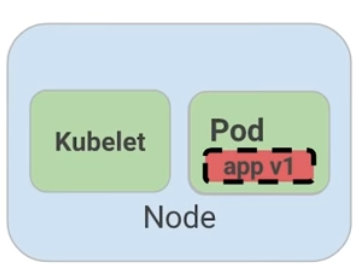
Figure 2: MHC de un pod muerto
Un periodo de tiempo establecido por el usuario indica la frecuencia con la que kubelet emite sondas para corroborar el estado del contenedor. Para este caso, el contenedor responde que esta muerto y la acción a ejecutar por Kubelet es el reinicio del contenedor, y posteriormente ejecutará en control de salud nuevamente.
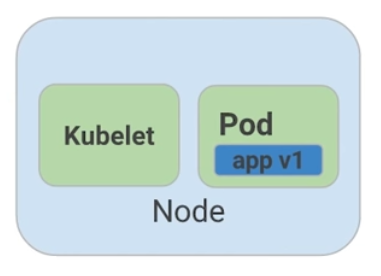
Figure 3: MHC de un pod vivo
Para esta oportunidad, todo esta funcionando como se espera, y el estado del contenedor esta perfecto, como lo determina el color azul.
Esto es a grandes rasgos un monitoreo de pods sobre controles de salud.
MHC archivos y comandos
Para complementar el monitoreo de controles de salud, es valido hacer las siguientes preguntas:
- ¿Cómo se ejecuta la sonda de preparación?
- ¿Con qué frecuencia se emite la sonda de preparación?
- ¿Con qué frecuencia se comprueba la sonda de vitalidad?
Las respuesta a estas preguntas se encuentran en el archivo
healthy-monolith.yaml y en el comando kubeclt describe pods healthy-monolith.
A continuación se muestra el contenido del archivo healthy-monolith.yaml.
$ cat pods/healthy-monolith.yaml
apiVersion: v1
kind: Pod
metadata:
name: "healthy-monolith"
labels:
app: monolith
spec:
containers:
- name: monolith
image: udacity/example-monolith:1.0.0
ports:
- name: http
containerPort: 80
- name: health
containerPort: 81
resources:
limits:
cpu: 0.2
memory: "10Mi"
livenessProbe:
httpGet:
path: /healthz
port: 81
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 15
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /readiness
port: 81
scheme: HTTP
initialDelaySeconds: 5
timeoutSeconds: 1
En este archivo se encuentra la respuesta de como se crea la prueba de
preparación. Se observa que hay información relevante al readinessProbe en
donde se especifíca que el retraso inicial para enviar la sonda al puerto 81
a través del protocolo HTTP es de 5 segundos. Por otra parte, la respuesta del
servidor, sea exitosa ó fallida, se envía 1 segundo después.
Para responder la segunda pregunta, es necesario usar el siguiente comando, para obtener la información relevante al monolith.
$ kubeclt describe pods healthy-monolith | grep Readiness
Readiness:
http-get http://:81/readiness
delay=5s
timeout=1s
period=10s
Se valida que hay un campo period que indica que cada 10 segundos la sonda de
preparación es ejecutada.
Para la última pregunta usamos un comando similar al anterior:
$ kubeclt describe pods healthy-monolith | grep Liveness
Liveness:
http-get http://:81/healthz
delay=5s
timeout=55
period=15s
En esta ocasión, el periodo definido para la prueba de vitalidad es de 15 segundos. Con estos ejercicios se refuerzan los procesos de monitoreo y pruebas de control.
Configuración de la aplicación
Muchas aplicaciones requieren de configuraciones secretas tales como certificados TLS para correr un ambiente de producción. Un problema que se observó anteriormente con el uso de docker fue que muchos desarrolladores queren publicar sus configuraciones propias en un contenedor público de docker, y la recomendación es no hacerlo.
En vez de compartir estás configuraciones, es posible usar herramientas de administración de de estrucutra dentro de los pods, pero no se debería seguir esta práctica.
La mejor alternativa es usar secretos y mapas de configuración para atender estos problemas. Ambas opciones son muy similares, y la única diferencia es que los mapas de configuración no tienen información delicada. Con estas herramientas se pueden usar variables de entorno y se establecen instrucciones para notificarle al pod que su figura tiene un nuevo cambio y de manera automática el pod se reiniciará de ser necesario.
Para crear un secreto desde un archivo, se ejecuta el siguiente comando:
$ kubeclt create secret generic tls-certs --form-file=tls/
La siguiente imagen describe cuál es el rol de los secretos:
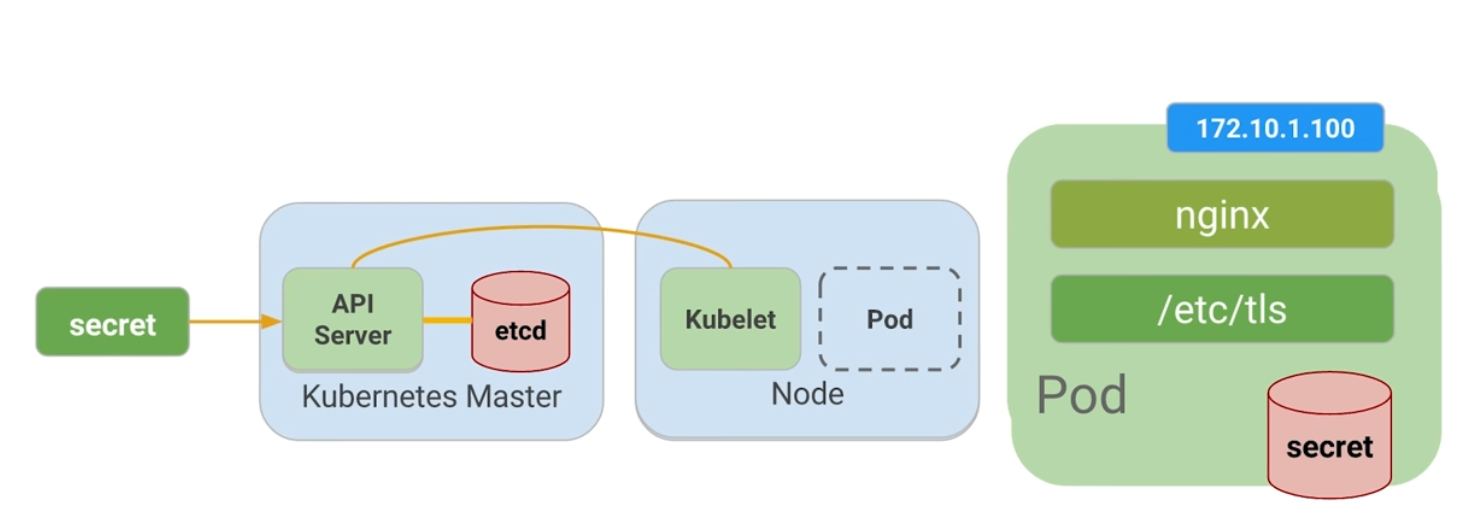
Figure 4: Secretos y mapas de configuración
Al crear el secreto, el pod kubernetes master es conciente de su existencia. Al momento de correr un pod con un secreto adjunto, primero se crea el pod y luego se monta el secreto como un volumen dentro del pod. De esta manera los creadores del pod tienen garantías de que sus configuraciones están en el pod antes de que el contenedor se inicie.
Con el volumen a disposición, se exponen las configuraciones desde el sistema de archivos a cualquier pod que se decida montar, los pods empiezan a conectarse entre sí y por último el contenedor se activa.
A modo de conclusión, los secretos se crean para almacenar datos sensibles de la aplicación, y los mapas de configuración se crean para almacenar datos de configuración para correr la aplicación.
Creando secretos
Ahora se va a crear un nuevo pod llamado monolíto seguro, cuya principal característica serán los accesos seguros al mismo a través de NGINX el cual servirá como un proxy inverso HTTPS. El contenedor de NGINX será desplegado en el mismo pod del contenedor del monolíto ya que estan fuertemente asociados.
Antes de usar el contenedor NGINX para revisar el tráfico HTTP, se van a necesitar algunos certificados TLS. Para este caso en puntual, los certificados TLS estarán almacenados en kubernetes como secretos. La seguridad en el acceso de un pod se obtiene con el uso de certificados. Se pueden revisar los certificados ejecutando el siguiente comando:
$ ls tls
ca-key.pem ca.pem cert.pem key.pem ssl-extensions-x509.cnf update-tls.sh
Los archivos cert.pem y el key.pem serán usados para el tráfico seguro sobre el servidor del monolito y el ca.pem será utilizado por los clientes HTTP como los cliente autorizados en los que se confía. Dado que los certificados que utiliza el servidor monolito fueron firmados por la CA representada por ca.pem, los clientes HTTP que confían en ca.pem podrán validar la conexión SSL al servidor monolito.
Para crear el secreto tls-certs a partir de los certificados TLS almacenados en el directorio tls, se corre el siguiente comando:
$ kubectl create secret generic tls-certs --from-file=tls/
Kubectl creará una clave para cada archivo en el directorio tls bajo el depósito secreto tls-certs. Utilice el comando kubectl describe para verificarlos:
$ kubectl describe secrets tls-certs
A continuación, es necesario crear una entrada de mapa de configuración para el archivo de configuración proxy.conf NGINX usando el comando kubectl create configmap, de la siguiente manera:
$ kubectl create configmap nginx-proxy-conf --from-file=nginx/proxy.conf
Utilice el comando kubectl describe configmap para obtener más detalles sobre la entrada del mapa de configuración nginx-proxy-conf:
$ kubectl describe configmap nginx-proxy-conf
TLS y SSL pueden ser temas confusos, es recomendable tener algunas bases sobre la capa de transporte seguro, para asimilar mejor sus usos.
Accediendo a una endpoint HTTPS
Ahora se va a exponder el pod NGINX con su respectivo mapa de configuración y afirmar los secretos del monolíto seguro en tiempos de ejecución. En primera medida se examina el archivo de configuración del monolíto seguro a través del siguiente comando:
$ cat pods/secure-monolith.yaml
Este seria el primer pod multi-contenedor. En la salida de este comando se puede observar las definiciones de ambos contenedores; NGINX y el monolito. Los contenedores son desplegados en el mismo pod ya que uno depende del otro. Los detalles sobre el monolito ya fueron señalados, y por parte de contenedor de NGINX hay dos cosas importantes por destacar.
La primera, es que en el archivo de configuración se agregó un cierre elegante al contenedor al incluir un gancho de ciclo de vida en la propiedad lifecycle. Por lo tanto para apagar el contenedor se ejecuta el comando especificado en dicha propiedad. Esto le permite a NGINX hacer la tarea apropiada, manejar todo el trafico restante y apagarse limpiamente.
Lo segundo, es que al final del archivo de configuración, se observan la definición de volúmenes correspondientes. De este modo, el contenedor NGINX puede acceder a los secretos y a los archivos de configuración.
Para crear el modelo seguro del pod, se usa el siguiente comando de kubectl:
$ kubectl create -f pods/secure-monolith.yaml
Para examinar el pod creado, se corre el siguiente comando:
$ kubectl get pods secure-monolith
Esta salida evidencia la que dos contenedores se están corriendo dentro del pod. Con estas instrucciones ya se tienen garantías de que el pod esta montado y se esta ejecutando. Para acceder a dicho pod, se ejecuta este comando en una segunda terminal:
$ kubectl port-forward secure-monolith 10443:443
Aquí es importante resaltar que el puerto 443 es por donde el contenedor NGINX esta escuchando las peticiones.
Por último, se usa el comando curl para probar el endpoint HTTP en una tercera terminal:
$ curl --cacert tls/ca.pem https://127.0.0.1:10443
Si todo funciona, se debe obtener la respuesta desde el servidor con el ya frecuente mensaje {"message":"Hello"} sobre la conexión segura HTTPS .
De manera complementaria, el comando kubectk logs ayuda a verificar el tráfico sobre el contenedor NGINX del pod monolito seguro.
$ kubectl logs -c nginx secure-monolith
El comando kubectl port-forward es grandioso para porbar pods directamente. No obstante, en producción los pods se exponen usando servicios
Revisión general de servicios
Como se vió anteriormente, los pods pueden ser reiniciados por multiples razones, como por ejemplo un fallo en un control de vitalidad, controles de preparación, entre otros.
Este escenario hace válida la siguiente pregunta: ¿Qué sucedería si se quisiera comunicar con un conjunto de pods que al reiniciarse pueden tener un dirección IP diferente? La respuesta esta en los servicios.
En vez de confiar en las direcciones IP de los pod, Kubernetes provee los servicios como un punto final para los pods. Los pods expuestos por los servicios están basados en un conjunto de etiquetas. Si los pods tienen las etiquetas correctas, ellos serán automaticamente recogidos y expuestos por los servicios.
Por otra parte, el nivel de acceso que los servicios suministran a los pods depende del tipo del servicio. Actualmente hay tres tipos:
- ClusterIP que es solo acceso interno.
- NodePort, que habilita al nodo una IP externa para compartir su acceso.
- LoadBalancer, que agrega un balanceador de carga desde el proveedor en la nube para forzar el tráfico desde el servicio hacia los nodos que están en él,
La siguiente imagen, es un resumen del contexto sobre el cual los servicios se desenvuelven.
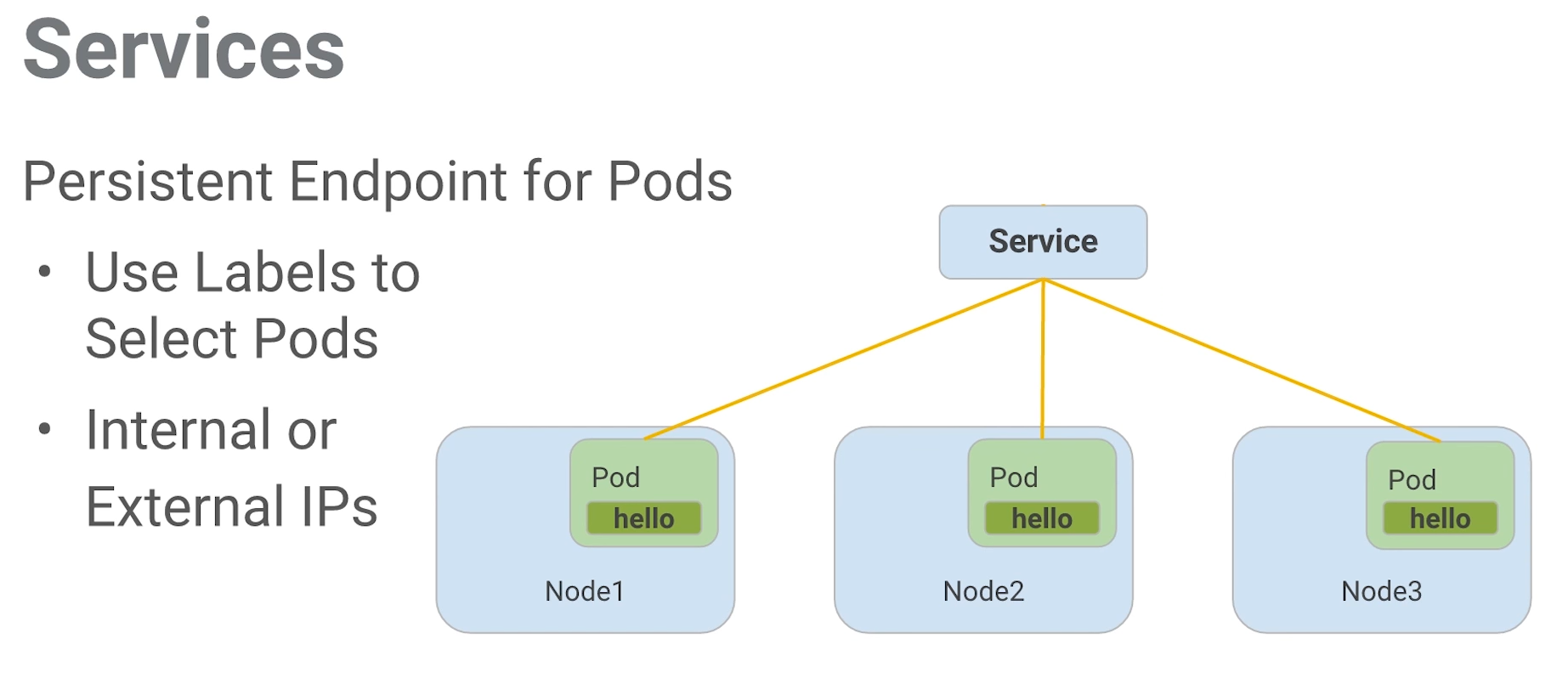
Figure 5: Servicios
Creando servicios
Es tiempo de exponer el pod del monolito seguro externamente a través de la creación de un servicio de kubernetes. Para empezar, es recomendable explorar el contenido del archivo de configuración del servicio a través del siguiente comando:
$ cat services/monolith.yaml
kind: Service
apiVersion: v1
metadata:
name: "monolith"
spec:
selector:
app: "monolith"
secure: "enabled"
ports:
- protocol: "TCP"
port: 443
targetPort: 443
nodePort: 31000
type: NodePort
Dos cosas por resaltar en esta salida. Primero, la sección selector la cual es utilzada para encotrar y exponer automaticamente cualquier pod con esas etiquetas app: "monolith" y secure: enabled.
Segundo, en la sección ports hay una nueva propiedad nodePort: 31000 el cual indica que por el puerto 31000 se destinará al tráfico externo y el puerto 443 es para NIGNX.
Con el siguiente comando se crea el servicio kubernetes:
$ kubectl create -f services/monolith.yaml
You have exposed your service on an external port on allnodes in your cluste. If you want to expose this service to the extenal internet, you may need to set up firewall rules for the service port tcp:31000 to serve traffic
service "monolith" created
Este mensaje indica que se esta usando el puerto 31000 para exponer el servicio. Eso significa que es posible tener colisiones de puertos si alguna otra aplicación intenta enlazarse a ese puerto en uno de los servidores.
Normalmente, es Kubernetes quien se encarga de manejar la asignación de puertos. No obstante, hacer dicha asignación manual, hace que sea más fácil de configurar los puntos de salud.
Para definir las reglas del firewall se ejecuta el siguiente comando:
gcloud compute firewall-rules create allow-monolith-nodeport --allow=tcp:31000
Con esta regla se habilita el trafico en el servició monolito sobre el puerto de nodo expuesto.
Ahora que todos esta configurado, ya se estaría en campacidad de golpear el servidor del monolito por fuera del cluster y sin usar el puento 40.
Para hacer la prueba, se recupera la dirección IP del nodo con el siguiente comando:
$ gcloud compute instances list
Posteriormente, se golpea el monolito seguro con curl.
$ curl -k https://104.197.223:31000
Sin embargo, no hay respuesta, ya que hace falta un paso: agregar las etiquetas a los pods.
Agregando etiquetas a los pods
Actualemente, el servicio de monolito seguro no tiene ningún endpoint. Una forma de solucionar este problema es usando el comando kubectl con la bandera de etiqueta:
$ kubectl get pods -l "app=monolith"
NAME
monolith
secure-monolith
Se puede observar que actualmente se tienen un par de pods corriendo con la etiqueta “monolith”. No obstante, al agregar la etiqueta “secure=enabled” se obtienen cero resultados:
$ kubectl get pods -l "app=monolith,secure=enabled"
En ese orden de ideas, el siguiente paso es validar cuales son las etiquetas de los pods seguros. Para ello se corre el siguiente comando:
$ kubectl describe pods pods secure-monolith | grep Labels
Labels: app=monolith
Esta salida indica el fallo. La etiqueta “secure=enable” no se ha agregado a los pods seguros. Para ello se ejecuta el siguiente comando:
$ kubectl label pods secure-monolith "secure=enabled"
pod "secure-monolith" labeled
Se corre el comando describe para ver si la etiqueta fue añadida:
$ kubectl describe pods secure-monolith | grep Labels
Labels: app=monolith,secure=enabled
He aquí la anhelada etiqueta “secure=enabled”. Ahora que las etiquetas estan configuradas apropiadamente, se valida la lista de endpoints sobre el servicio del monolito:
$ kubectl describe services monolith | grep Endpoints
Endpoints: 10.52.1.4:443
Ahora hay un resultado. Al correr nuevamente el curl, se logra la respuesta.
$ curl -k https://104.197.223:31000
{"message": "Hello"}
Outro
Al igual que Docker, Kubernetes hace que sea fácil correr y hacer introespección en las aplicaciones. Esto es lo que se llama automatización. En esta guía se revisarion varias de la primitivas de despliegue que Kubernetes ofrece a los desarrolladores. En este punto, se debe ser consciente del poder de abstracción de alto nivel que ofrece Kubernetes lo cual permite tener más enfoque sobre la aplicación y no sobre la administración de despliegues.
Sin embargo, estas son tan solo las bases. Es momento de retirar la ruedas de entrenamiento y aprender no solo a escalar la aplicación de manera automática, sino también, realizar actualizaciones continuas sin tiempos de inactividad y como trabajar con información delicada.